E aí galera, belezura?
Nesse artigo vamos fazer uma otimização de performance e consumo de recursos no SQL Server fazendo o uso de índices, com o adendo de nos atentarmos aos “Key Lookups”. Bora!
Antes de qualquer coisa, caso você não saiba o que é um índice de banco de dados, pode dar uma olhada nesse cara aqui.
A ideia, é fazer uma demonstração de maneira prática, se fossemos nos atentar a cada detalhe, e focar na teoria disso tudo, íamos nos estender muito e ficar bem cansativo, então vamos direto ao ponto.
Hora da prática!
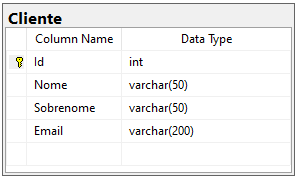
Imagine que em um banco de dados qualquer, tenhamos uma tabela de Cliente, criada da seguinte maneira:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| CREATE TABLE Cliente ( | |
| Id INT IDENTITY(1,1) NOT NULL, | |
| Nome VARCHAR(50) NOT NULL, | |
| Sobrenome VARCHAR(50) NOT NULL, | |
| Email VARCHAR(200) NOT NULL, | |
| CONSTRAINT Cliente_PK PRIMARY KEY (Id) | |
| ) |
Simples, certo? Visualizando de maneira gráfica, a tabela fica assim:
Para realizarmos nossos testes, vamos popular essa tabela com 1.000.000 (um milhão) de registros. Para fazer isto rodamos o seguinte comando:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| DECLARE @Contador INT = 1000000 | |
| WHILE @Contador > 0 | |
| BEGIN | |
| INSERT INTO Cliente(Nome, Sobrenome, Email) | |
| VALUES ( | |
| SUBSTRING(REPLACE(CONVERT(VARCHAR(250),NEWID()), '-', ''),1,15), | |
| SUBSTRING(REPLACE(CONVERT(VARCHAR(250),NEWID()), '-', ''),1,15), | |
| LOWER(SUBSTRING(REPLACE(CONVERT(VARCHAR(250),NEWID()), '-', ''),1,30)) + '@email.com' | |
| ) | |
| SET @Contador = @Contador – 1 | |
| END |
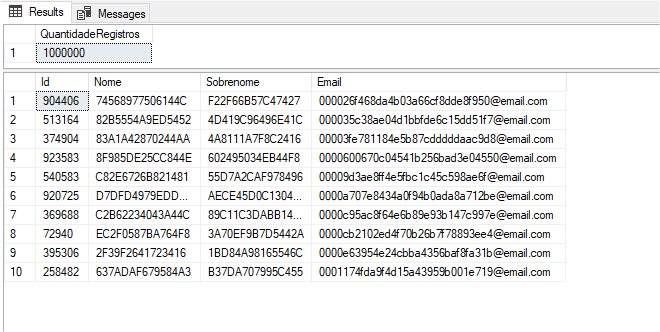
Abaixo, vamos rodar um comando para verificar a quantidade de registros na tabela e também faremos a seleção dos 10 primeiros registros para verificarmos como ficaram nossos dados:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| SELECT COUNT(*) AS QuantidadeRegistros FROM Cliente | |
| SELECT TOP 10 * FROM Cliente |
O resultado é o seguinte:
Com a base pupulada, vamos alterar um registro qualquer, somente para fins didáticos, para procurar por um e-mail mais “bonitinho” do que um combinado de caracteres, veja:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| UPDATE Cliente | |
| SET Nome = 'Vinicius', | |
| Sobrenome = 'Mussak', | |
| Email = 'vinicius.mussak@outlook.com' | |
| WHERE Id = 333123 |
A consulta que vamos trabalhar é a que vou exibir a seguir, não vamos mexer em nada na query em si, somente nos índices, vejam a query:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| SELECT Id, | |
| Nome, | |
| Sobrenome, | |
| FROM Cliente | |
| WHERE Email = 'vinicius.mussak@outlook.com' |
Primeiro problema
Logo de cara, temos o seguinte plano de execução:
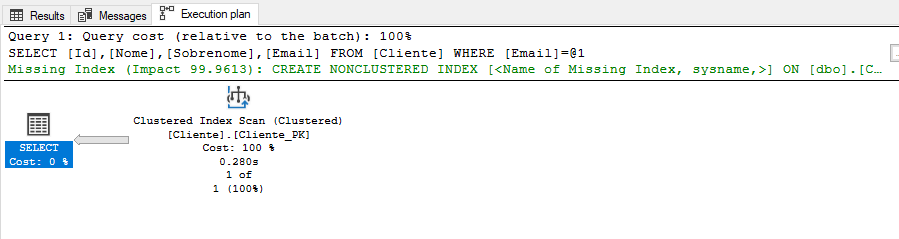
Os detalhes:

Reparem na propriedade “Number of rows read“, que é 1.000.000, ou seja, todos os registros da tabela, isso significa que o banco de dados faz mais ou menos isso aqui:
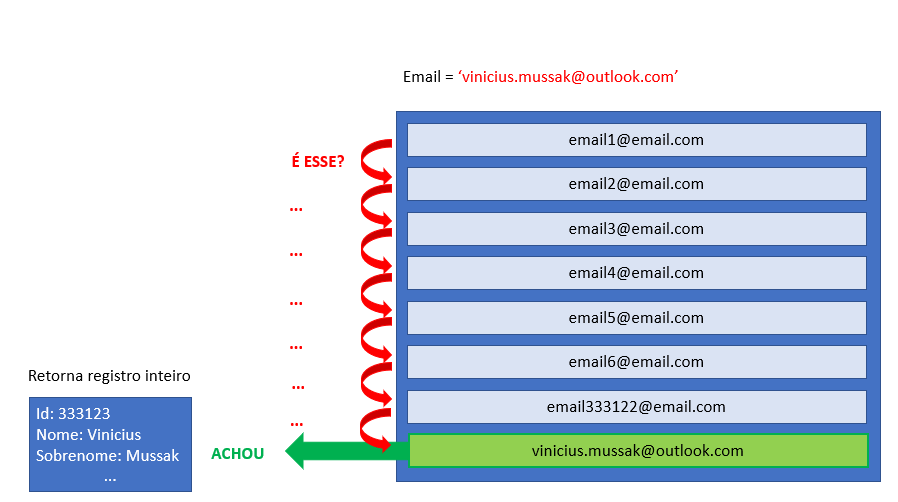
O mecanismo percorre registro por registro “perguntando” se a linha em questão possui o e-mail que estamos buscando, e quando a condição é satisfeita, o registro é retornado para a consulta.
Vejam que para retornar esse registro localmente e sem concorrência, o banco de dados precisou de 280ms, e percorreu toda a tabela, gerando um custo de I/O consideravelmente alto.
Primeira solução
Para sanarmos esse problema, de percorrer a tabela toda, vamos criar um índice pelo campo “Email”, que funciona como um índice de um livro mesmo, mostrando fisicamente onde fica esse registro na tabela facilitando a busca. Para criar o índice, utilizamos o seguinte trecho de código:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| CREATE INDEX IDX_ClienteEmail | |
| ON Cliente(Email) |
A sintaxe é simples, um índice precisa ter um nome, uma tabela e um ou vários campos a serem indexados.
Se executarmos a mesma query:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| SELECT Id, | |
| Nome, | |
| Sobrenome, | |
| FROM Cliente | |
| WHERE Email = 'vinicius.mussak@outlook.com' |
agora, o plano de execução fica dessa maneira:
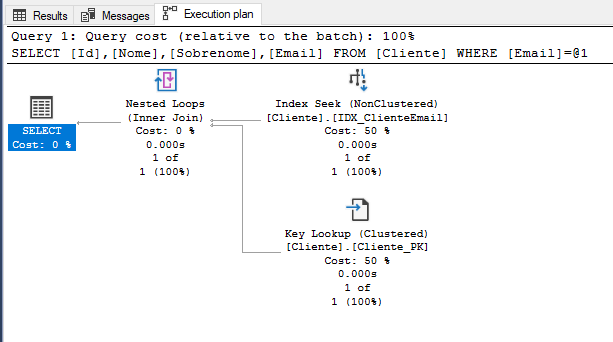
Em detalhes:


Agora podemos observar que a consulta é realizada em duas partes.
O problema foi resolvido, pois o tempo de leitura foi para 0ms para cada parte da consulta, e o número de linhas lidas foi para 1, ou seja, já economizamos tempo e I/O do nosso banco de dados.
As duas etapas que são feitas na consulta são:
1ª – Busca do registro na tabela utilizando o índice “IDX_ClienteEmail” (que é o que a gente queria que acontecesse, né?);
2ª – Busca do registro utilizando a PK da tabela, que é o Id. (WTF?);
Segundo problema
Mas porque isso acontece?
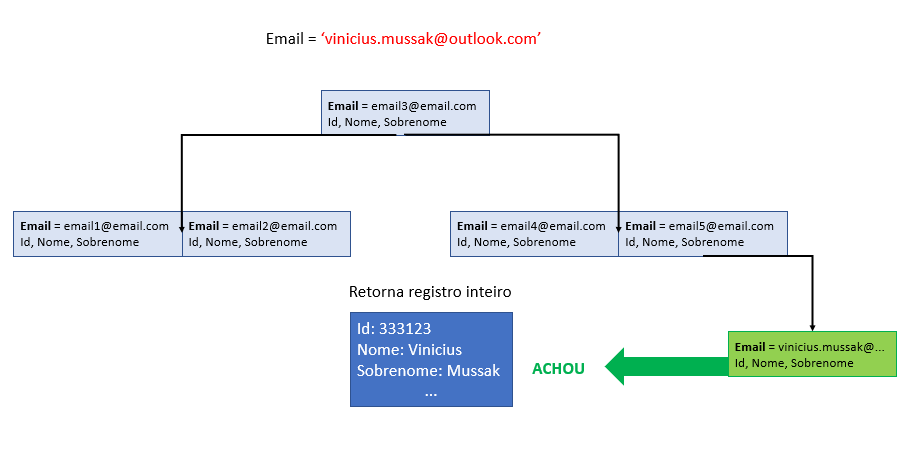
Vou exemplificar abaixo para entendermos melhor, vejam:
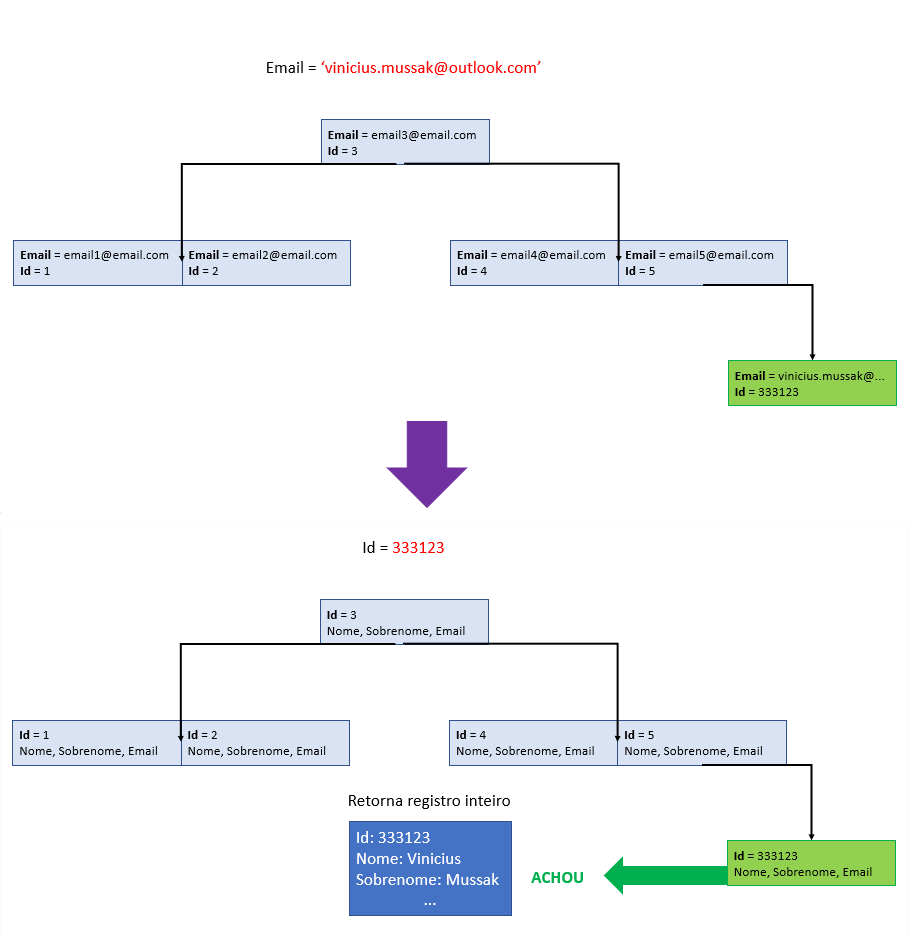
Explicando a imagem acima:
Na primeira parte, que é a busca pelo índice que criamos, o banco de dados percorre cada nó para verificar se a condição que queremos é satisfeita (Email igual ao que estamos buscando), porém, o nosso índice não “encontra” todos os atributos da tabela, ele encontra apenas o campo “Email”, que é o campo indexado, e a PK da tabela, que é o campo Id.
Como em nossa query buscamos os campos: “Id”, “Nome”, “Sobrenome” e “Email”, o banco de dados precisa percorrer a tabela novamente para encontrar os demais atributos que precisamos buscar, chamado de “Key Lookup“. Ou seja, eu busco a chave primária pelo índice que eu preciso, e depois preciso buscar o resto dos dados olhando para a chave primária.
Só que dessa vez, não precisamos ir de linha a linha, pois temos o Id exato que queremos buscar. Por isso a busca pela PK, que é nosso índice clusterizado, e que retorna todos os atributos da tabela.
Deu pra entender até aqui? Espero que sim!
Solução final
Em certos casos, o banco de dados “prefere” nem utilizar o índice por conta do Key Lookup, pois é uma tarefa muito custosa.
Para removermos isso, e buscarmos todos os atributos que precisamos da tabela de uma vez só, vamos utilizar o comando “INCLUDE”, vejam:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| CREATE INDEX IDX_ClienteEmail | |
| ON Cliente(Email) | |
| INCLUDE (Nome, Sobrenome) | |
| WITH (DROP_EXISTING = ON) |
Vejam que incluímos os campos que precisamos buscar dentro de “INCLUDE”, com isso conseguiremos remover o Key Lookup.
A termo “DROP_EXISTING = ON” é somente para excluirmos o índice que já existe e substituir pelo novo.
E quando executamos a query:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| SELECT Id, | |
| Nome, | |
| Sobrenome, | |
| FROM Cliente | |
| WHERE Email = 'vinicius.mussak@outlook.com' |
Vejam como fica o plano de execução:
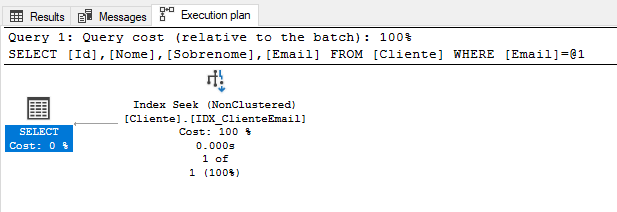
Em detalhes:
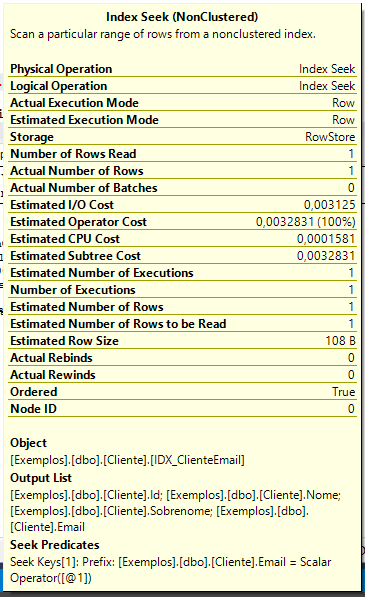
Ou seja, a nossa consulta agora tem apenas 1 etapa, que é somente a busca pelo índice “IDX_ClienteEmail” que busca dados da tabela “Cliente” pelo campo “Email”, lê apenas 1 linha em 0ms. Isso quer dizer que o consumo de recursos é mínimo e o tempo também.
Para exemplificar, esse índice funciona dessa maneira:
Não precisamos fazer uma busca pela PK, pois os atributos da tabela que precisamos já estão incluídos no próprio índice.
Fácil?
Os códigos utilizados estão disponíveis no GitHub: https://github.com/vmussak/performance-sql-index-key-lookup
Por hoje é só isso, qualquer dúvida ou sugestão, estou à disposição! Até mais 😀

Foda! De extrema importância esse tema (indices) e muito didático. Parabens Brother!
GostarGostar
Valeu pelo feedback Karpinski! Fico feliz que tenha sido útil 😀
GostarGostar
Excelente Mussakera, muito interessante esse lance do include, não conhecia e também não sabia que era feito uma segunda query pela pk. Uma dúvida, como faria a seleção dos campo para criar index para uma base que será consumida pelo Power BI por exemplo?
GostarGostar
Opa Luis! Valeu pelo feedback 🙂
Cara, você pode criar os índices dentro da ferramenta do power BI mesmo, respondi sua pergunta? Se não, me chama e conversamos!
Abraço!
GostarGostar
Boa Mussak, respondeu sim, obrigado brother
GostarGostar