E aí galera! Tudo certo?
Hoje vamos começar uma série sobre a certificação 70-486 da microsoft, pretendo abordar os tópicos pertinentes à este exame, vai ficar um pouco extensa mas vai valer a pena 😀

Aplicativo e camadas
Então galera, antes de qualquer coisa, vamos à definição de “aplicativo”, que é simplesmente um conjunto de funcionalidades, certo?! São telas que exibem informações, tomam decisões de negócio e persistem dados.
Mas espera aí, não é bem assim, tudo na tela, a nossa aplicação deve ser dividida em camadas; vocês sabem o que são camadas? Com certeza né! Mas mesmo assim vou deixar uma definição aqui: Uma camada é uma junção lógica de códigos que funcionam em conjunto para cumprir uma responsabilidade em comum. Ou seja, camadas trabalham em conjunto para produzirem o objetivo final, que é o funcionamento da aplicação.
Acesso à dados
O acesso à dados é uma parte bastante importante da aplicação, pois basicamente a sua aplicação é baseada em acessar e persistir dados, e por esse motivo, quando iniciamos a construção de uma aplicação, devemos analisar as necessidades sobre os dados no início do processo.
Será que já temos uma base de dados existente e vamos consumi-la? Ou vamos criar tudo do início? São algumas das perguntas que devemos nos atentar ao fazer esse tipo de levantamento, pois à partir desse ponto que podemos dar um passo e decidir como acessar os dados.
Como acessar os dados?
As duas formas primárias de acesso à dados são:
- ORM (Object relational mapper): ou mapeamento objeto-relacional, é uma aplicação ou sistema que auxilia na conversão dos dados providos por um banco de dados relacional para o modelo orientado à objetos. O ORM é o cara que vai fazer o trabalho de buscar e persistir dados no banco, tudo isso sem precisarmos
escrever instruções SQL. Alguns exemplos de ORM são: Entity Framework, NHibernate e Linq-to-SQL.- Exemplo de um insert usando Entity Framework:
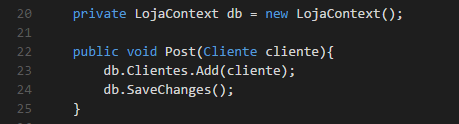
- Exemplo de um insert usando Entity Framework:
- Faça o seu próprio componente! Isso implica que você vai ter que gerenciar todas as conversões do banco de dados para a aplicação. Essa abordagem é mais indicada quando os dados providos do banco não são modelados de acordo com a aplicação, ou quando estamos trabalhando com uma fonte de dados NoSQL, por exemplo.
- Exemplo de um insert usando ADO.NET:

- Exemplo de um insert usando ADO.NET:
O tipo de modelo de acesso que você vai utilizar influencia no restante do planejamento da aplicação; se criar o próprio acesso, você será minimamente afetado pela existência de um
modelo de dados ou não. Porém, se você está utilizando ORM, sua flexibilidade será afetada pela ferramenta que usa. O linq-to-SQL por exemplo, funciona apenas com bancos de dados pré existentes. Já o Entity Framework e o NHibernate permitem a criação dos seus modelos orientados à objeto para posteriormente criar o banco de dados baseado nas classes.
Model first
Esta abordagem permite-nos criar o nosso modelo conceitual, usando o Visual Studio, através da criação de um arquivo .EDMX, onde vamos ter o diagrama do nosso modelo, e depois, com base neste, criar a base de dados.
Code first
Já com o Code first, nós escrevemos as nossas classes primeiro, para depois gerar o banco de dados onde vamos persistir os dados, mas dessa vez, nada de .EDMX. Ele é bastante voltado para desenvolvedores, pois eles podem codificar as classes de domínio e assim gerar o banco de dados sem auxílio algum.
Se quiser saber mais sobre Model first, Code first e Database first, veja aqui.
Em geral
Depois disso tudo esclarecido, e de saber se vamos fazer um novo banco de dados, ou trabalhar com um existente; a parte da escolha da tecnologia para suprir as necessidades do projeto vai depender muito mais de como está o seu banco de dados atual e as preferências e pontos fortes da equipe de desenvolvimento, do que a tecnologia em si. Agora precisamos saber, em que lugar vamos acessar os nossos dados, é o assunto do próximo tópico!
Repository Pattern
Depois de escolher a tecnologia à ser usada, precisamos decidir como vamos acessar nossos dados. O pattern de acesso a dados primário em C# é o Repository pattern, que em uma visão bem macro, é a abstração entre a camada de acesso a dados e a lógica de negócios.
Essa abstração ajuda à lidar com alterações em ambas as partes. E também podemos abstrair de onde provém os dados, que podem vir de um banco relacional, NoSQL, de um .txt ou de um .csv, pois o repositório me garante que vai devolver uma instância da classe “Cliente“, por exemplo.
Outra vantagem de usar o Repository pattern é o uso de TDD, pois permite que
você substitua a conexão de dados real por um Mock, com dados conhecidos.
Para usá-lo devemos criar uma classe e uma interface representando o nosso repositório.
Ou seja, quando precisamos usar o repositório, temos que instanciar uma classe que
contempla as assinaturas da nossa interface, facilitando o uso de testes.
Caso queiram ver mais sobre Repository pattern, podem dar uma olhada aqui.
Por hoje é só, qualquer dúvida ou sugestão, estou à disposição! Até mais 😀
