E aí galera! Tudo certo?
Depois de um tempo sem falar de performance, vamos voltar com um assunto bem legal! A leitura de dados de um banco de dados. Será que estamos fazendo da melhor maneira possível? Vamos ver!
Depois que nós já vimos dicas sobre manipulação de strings, coleções e conversões chegou a hora de vermos alguma coisa relacionada com banco de dados.
Provavelmente você trabalha ou já trabalhou em algum projeto que utiliza as famosas Stored Procedures ou o bom e velho ADO .NET para acessar o banco de dados né? E quase sempre o que vemos por aí é algo parecido com isso:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| public IEnumerable<Cliente> BuscarClientes() | |
| { | |
| var query = "SELECT TOP 100000 * FROM Cliente"; | |
| var lstCliente = new List<Cliente>(100000); | |
| var cmd = new SqlCommand(query, _connection); | |
| using (var reader = cmd.ExecuteReader()) | |
| { | |
| if (reader.HasRows) | |
| { | |
| while (reader.Read()) | |
| lstCliente.Add(new Cliente | |
| { | |
| Id = (int)reader["Id"], | |
| Nome = reader["Nome"].ToString(), | |
| DataNascimento = (DateTime)reader["DataNascimento"], | |
| ClienteEspecial = (bool)reader["ClienteEspecial"], | |
| NomeDaMae = reader["NomeDaMae"].ToString(), | |
| QuantidadeFilhos = (byte)reader["QuantidadeFilhos"] | |
| }); | |
| } | |
| } | |
| return lstCliente; | |
| } |
Claro que temos todos os encapsulamentos e tal, mas no fim das contas, é isso, não?
A sugestão que vou fazer, é para utilizarmos o método Get[type], que busca através do índice da coluna e não pelo nome, como vimos no exemplo acima.
O que vai acontecer, é que vamos trocar
Id = (int)reader["Id"]
por
Id = reader.GetInt32(0)
Porém, convenhamos que buscar as colunas por índice não é nada sugestivo né? Por conta disso, a outra sugestão é utilizar o método GetOrdinal, que recupera o índice da coluna pelo nome, dessa maneira:
int id = reader.GetOrdinal("Id");
Id = reader.GetInt32(id)
O código fica mais ou menos dessa maneira:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| public IEnumerable<Cliente> BuscarClientes2() | |
| { | |
| var query = "SELECT TOP 100000 * FROM Cliente"; | |
| var lstCliente = new List<Cliente>(100000); | |
| _connection.Open(); | |
| var cmd = new SqlCommand(query, _connection); | |
| using (var reader = cmd.ExecuteReader()) | |
| { | |
| if (reader.HasRows) | |
| { | |
| int id = reader.GetOrdinal("Id"), | |
| nome = reader.GetOrdinal("Nome"), | |
| dataNascimento = reader.GetOrdinal("DataNascimento"), | |
| clienteEspecial = reader.GetOrdinal("ClienteEspecial"), | |
| nomeDaMae = reader.GetOrdinal("NomeDaMae"), | |
| quantidadeFilhos = reader.GetOrdinal("QuantidadeFilhos"); | |
| while (reader.Read()) | |
| lstCliente.Add(new Cliente | |
| { | |
| Id = reader.GetInt32(id), | |
| Nome = reader.GetString(nome), | |
| DataNascimento = reader.GetDateTime(dataNascimento), | |
| ClienteEspecial = reader.GetBoolean(clienteEspecial), | |
| NomeDaMae = reader.GetString(nomeDaMae), | |
| QuantidadeFilhos = reader.GetByte(quantidadeFilhos) | |
| }); | |
| } | |
| } | |
| return lstCliente; | |
| } |
Para medir a performance das duas maneiras, utilizei a classe Stopwatch, que mede o tempo de execução de um bloco de código; só para vocês se situarem, ficou desse jeito:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| if (reader.HasRows) | |
| { | |
| var time = new Stopwatch(); | |
| time.Start(); | |
| while (reader.Read()) | |
| lstCliente.Add(new Cliente | |
| { | |
| Id = (int)reader["Id"], | |
| Nome = reader["Nome"].ToString(), | |
| DataNascimento = (DateTime)reader["DataNascimento"], | |
| ClienteEspecial = (bool)reader["ClienteEspecial"], | |
| NomeDaMae = reader["NomeDaMae"].ToString(), | |
| QuantidadeFilhos = (byte)reader["QuantidadeFilhos"] | |
| }); | |
| time.Stop(); | |
| Console.WriteLine("Tempo buscando pelo nome da coluna: {0}", time.Elapsed); | |
| } |
Em um select com 6 colunas, e pouco mais de 2 milhões de registros, tivemos esse resultado:
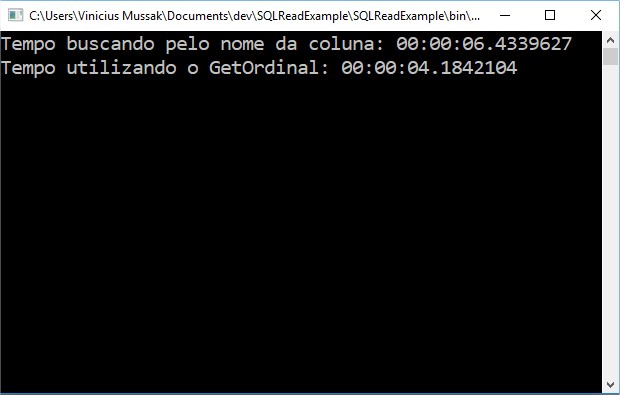
O método que utilizou o GetOrdinal obteve a performance maior com pouco mais de 2 segundos de diferença.
Os exemplos de código estão disponíveis no GitHub: https://github.com/vmussak/PerformanceReadSQLExample
Por hoje é só isso, qualquer dúvida ou sugestão, estou à disposição! Até mais 😀
